Building a Dota 2 Hero Similarity Map
The map is interactive — you can zoom and pan around.
In my previous post, I described how we generate balanced Dota 2 teams for our LAN parties using a custom MMR-based matchmaking system. That part works surprisingly well - but one part of our setup still feels completely random: hero selection.
At our LAN parties, each player currently gets three random heroes to choose from. We do this deliberately to keep things unpredictable and fun - not grinding the same one hero for performance. It’s chaotic, entertaining, and sometimes completely broken. But it often leads to:
- bad player-hero fit (you get a hero you’ve never touched)
- completely unbalanced team compositions (no disables, five carries, etc.)
My brother and I wanted to fix that without losing the chaos. We thought: what if we generate Team A’s heroes at random, then match players by MMR and give Team B similar heroes - so both sides get comparable compositions?
That way, drafts stay fun and unpredictable but fair.
To do that, we first needed a measure of hero similarity.
What are Dota 2 heroes?
For those who haven’t played: Dota 2 is a 5-versus-5 strategy game where each player controls one hero out of 126 available characters. Each hero has unique abilities and a defined role: some focus on dealing damage (carries), some protect teammates (supports), and others start fights (initiators). In real games, heroes are banned and picked in turns, forming complex drafts that depend on synergy and counter-picks.
Those patterns - who gets picked with whom and when - encode a lot of information about how heroes relate to each other. That’s exactly what I wanted to extract.
The data
I used professional match drafts from Kaggle’s Dota 2 Pro League dataset.
Each row describes one step in a match’s pick/ban phase:
| match_id | order | team | is_pick | hero_id |
|---|---|---|---|---|
| 12345 | 1 | 0 | False | 65 |
| 12345 | 2 | 1 | False | 46 |
| 12345 | 3 | 0 | True | 27 |
| 12345 | 4 | 1 | True | 90 |
| 12345 | 5 | 0 | True | 19 |
So at step 3, Team 0 picked hero #27.
I can reconstruct every match’s draft - which heroes were already chosen, which were unavailable, and what was picked next.
Across the last 3 years, the dataset covers about 77,000 matches — plenty for this kind of modeling.
The model
I decided to train a simple neural network that learns these drafting patterns. The idea is straightforward:
Given 4 heroes on a team, predict 5th hero.
If Team 0 has already picked Dazzle, Juggernaut, Centaur, and Skywrath Mage, the model learns that the next pick is often something like Queen of Pain - a mid-lane hero that complements that lineup.
Heroes that appear in similar team contexts should end up close together in the model’s internal representation.
import torch, torch.nn as nn, torch.nn.functional as F
HERO_COUNT = 126
HIDDEN = 64
EMBED_DIM = 32
class HeroPredictor(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(HERO_COUNT, HIDDEN)
self.fc2 = nn.Linear(HIDDEN, HIDDEN)
self.fc3 = nn.Linear(HIDDEN, EMBED_DIM)
self.output = nn.Linear(EMBED_DIM, HERO_COUNT)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
h = F.relu(self.fc3(x))
logits = self.output(h)
return logits
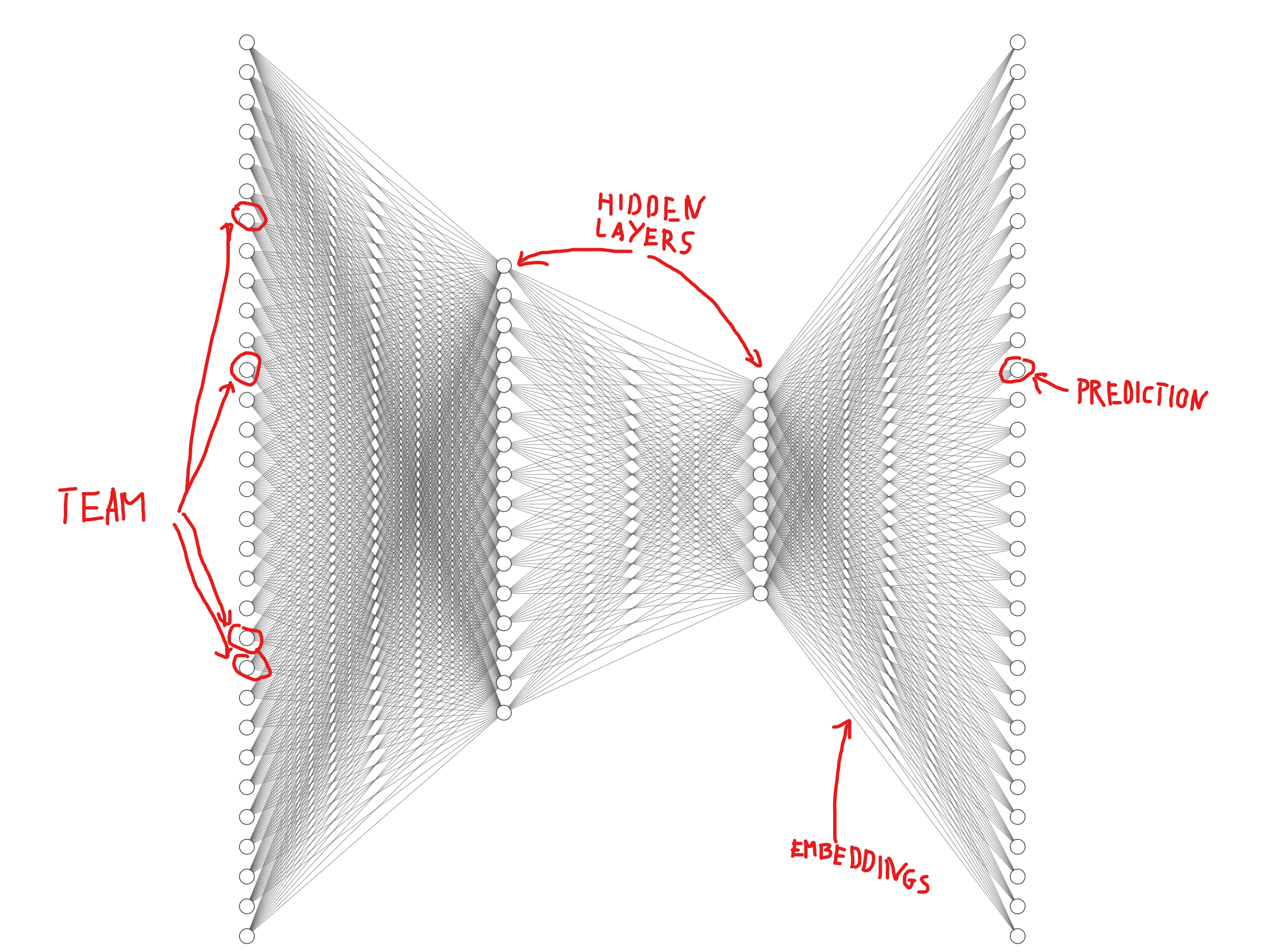
Each input is a one-hot encoded vector of length 126, where each position corresponds to one hero:
1 means the hero is picked, 0 means it’s not.
The network outputs a probability distribution over all heroes - which hero comes next.
It’s trained with simple cross-entropy loss and masked invalid heroes (already picked or banned). I used AdamW for optimization and a small amount of label smoothing for stability.
Only ~200 lines of code are needed to recreate all the results. The full Colab notebook isn’t that small though; it includes experiments, retries, and some LLM-generated chaos. Beware of dragons.
It takes ~1h (~200 epochs) of training on my laptop’s RTX 4070 GPU for the model to reached stable accuracy. I left the training running for a bit longer than necessary.
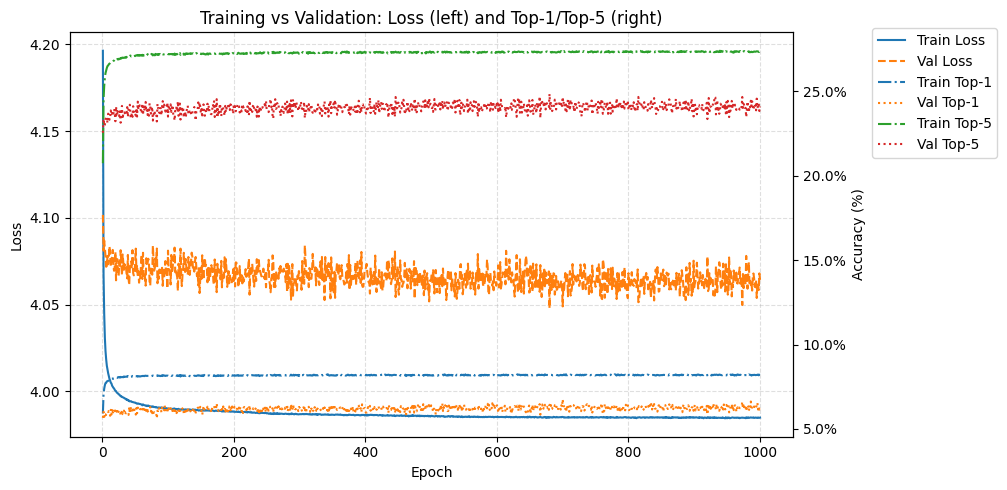
During training I tracked both loss (how wrong the model’s predictions are) and Top-k accuracy, where Top-1 means the correct hero was the single most likely prediction, and Top-5 means it appeared anywhere in the five most likely heroes. Validation (“val”) uses unseen matches to check how well the model generalizes beyond the training data.
The model’s accuracy isn’t high — Top-1 = 6.3%, Top-5 = 24.1% — but that’s fine, because the goal isn’t prediction accuracy. What matters is how it represents heroes internally.
Extracting hero embeddings
Embeddings are the model’s internal “language” for representing heroes. Each hero ends up as a 32-dimensional vector — the row of weights that connects the last hidden layer to that hero’s output.
Heroes that appear in similar team contexts have embeddings that lie close together in this space, and that geometric proximity becomes our hero-similarity metric.
I normalized embeddings and projected them from 32D space to 2D using UMAP to see what the network had learned. I tried PCA at first, but it’s not as good.
import umap, matplotlib.pyplot as plt
import torch.nn.functional as F
hero_embeds = model.output.weight.detach().cpu()
hero_embeds = F.normalize(hero_embeds, dim=1)
um = umap.UMAP(n_neighbors=20, min_dist=0.05, metric="cosine", random_state=0)
embeds_2d = um.fit_transform(hero_embeds)
plt.figure()
plt.scatter(embeds_2d[:,0], embeds_2d[:,1], s=20, alpha=0.7)
plt.show()
The result
The resulting map was shockingly coherent.
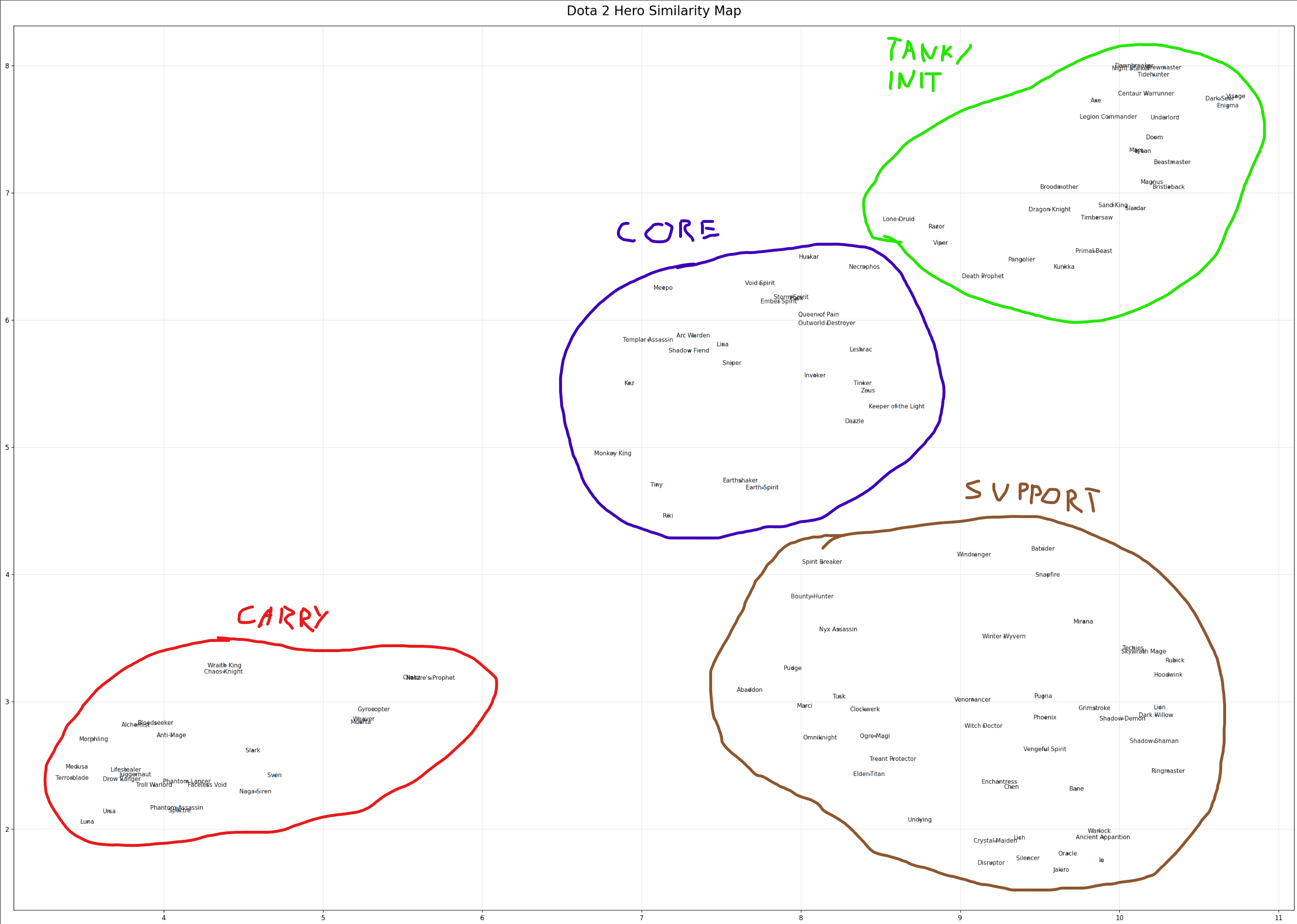 Each point is a hero. Distance on the map roughly reflects how often heroes appear together in similar lineups.
Each point is a hero. Distance on the map roughly reflects how often heroes appear together in similar lineups.
Clusters appeared naturally:
- carries and ranged cores together,
- tanky initiators grouped on another side,
- supports and cores forming their own island.
All that from just learning which hero tends to follow which. No manual labels, no human rules.
It’s one of those moments where you see a neural network "discover" the game’s structure on its own.
These clusters are only for visualization — they’re not used directly in the matchmaking logic.
In the actual system, I only use the numerical embeddings to compute hero-to-hero similarity.
The map just helps to see that the model learned something meaningful.
Hero similarity
Computing cosine similarity map from embeddings is trivial:
similarity = np.matmul(hero_embeds, hero_embeds.T)
From that I generated a list of the most similar heroes for each character (similarity index in parentheses):
Anti-Mage → Troll Warlord (0.97), Juggernaut (0.95), Bloodseeker (0.94), Ursa (0.94), Phantom Lancer (0.94)
Axe → Tidehunter (0.94), Mars (0.93), Underlord (0.93), Legion Commander (0.93), Beastmaster (0.92)
Bane → Vengeful Spirit (0.91), Jakiro (0.90), Disruptor (0.88), Lion (0.88), Crystal Maiden (0.88)
Bloodseeker → Anti-Mage (0.94), Phantom Lancer (0.92), Juggernaut (0.92), Troll Warlord (0.90), Ursa (0.89)
Crystal Maiden → Disruptor (0.95), Lich (0.89), Bane (0.88), Oracle (0.86), Jakiro (0.84)
Drow Ranger → Ursa (0.95), Troll Warlord (0.94), Juggernaut (0.93), Morphling (0.93), Phantom Lancer (0.92)
Earthshaker → Earth Spirit (0.91), Tiny (0.86), Sand King (0.84), Invoker (0.82), Kunkka (0.81)
(...)
I shared the similarity map and this list with my friends - all long-time Dota players - and everyone said the results match their intuition almost perfectly. Carries cluster with similar carries, supports with similar supports.
Using it for matchmaking
For our LAN parties, this means we can now build drafts that stay fair and interesting - even when everything is still random.
Here’s how it works now:
-
Each player on Team A still gets to pick their hero from 3 random heroes, just like before.
-
Then for Team B, each matching player (based on their ELO rating) receives 3 heroes most similar to their opponent’s 3.
So instead of both teams rolling completely independent random sets, Team B’s lineup mirrors Team A’s roles - carries against carries, supports against supports, offlaners against offlaners - but using different heroes that fill the same role.
Example:
Team A best player picks 1 hero from:
1) HERO A (e.g. Anti-Mage)
2) HERO B (e.g. Axe)
3) HERO C (e.g. Bane)
Team B best player picks 1 hero from:
1) hero most similar to HERO A (e.g. Troll Warlord)
2) hero most similar to HERO B (e.g. Tidehunter)
3) hero most similar to HERO C (e.g. Vengeful Spirit)
same goes for the remaining players
Each player still makes a random-flavored choice, but both teams end up with comparable roles, disables, and lane balance. It keeps the matchups fun, fair, and far less dependent on pure luck.
What’s next
It won’t fix individual player-hero preferences yet, but it already makes drafts more consistent and enjoyable.
And honestly, seeing a neural network uncover Dota 2’s hidden structure from nothing but pick orders was worth it all by itself.
The best part? None of this was hard-coded or labeled — the model learned it purely from patterns in how pros draft heroes. It’s a neat example of how simple ML tools can reveal real structure hidden in messy data.
And the real best part? Our next LAN party is in just a few weeks!
